

Ananay Agarwal & S.V. Sai Vikas
02 June 2021 | 2 min read
Why use Surf?
Let’s say you are working with a list that consists of names and addresses of individuals who have changed their residential address in the last one year in a small town. You are interested in knowing the proportion of people who have moved addresses in the last one year .On this list is a “Mr. Kailash Mehra” who lived in A-961 Indira Nagar as of January 1, 2020. Also on this list is a “Shri. Kailasha Mehraa” who is at C-116 Indira Nagar on January 1, 2021. But is “Mr. Kailash Mehra” who lived in A-961 Indira Nagar the same as “Shri. Kailasha Mehraa” who is at C-116 Indira Nagar? How do we tell whether this is the same individual? Did the person entering the names in the database make a mistake? Or maybe they are actually two different individuals? If you are in the same town, you can decide to actually send someone to find out or go out yourself. This is alright if you have a handful of these cases, however, what if you have millions of such cases? What will you do then?
While we do not work on lists of names and addresses, we work with lists of names of individuals who have contested elections (Vidhan Sabha and Lok Sabha) in independent India. This problem of resolving whether one person or in our case one politician’s name is spelled in 5 different ways or whether the 5 different names are actually 5 different individuals, is where Surf comes to the rescue! As we work with electoral data, instead of addresses, we work with votes the candidate received, the party they contested from, constituency name, their gender etc.
Surf was originally developed by Shivangi Tikekar and Sudheendra Hangal to handle this problem. The purpose of Surf was to be able to tell with some level of confidence whether similar looking and sounding names actually represented the same individual or not. In order to help solve this problem, other pieces of information are harnessed such as the gender, constituency, caste, jati, and age. While the tool can be improved, in our experience, it is sufficiently developed and user-friendly, and we think it can be used to help solve this issue for all kinds of names – individuals, geographical places, party names etc.
What is Surf?
Surf is a tool built by TCPD to ‘resolve’ Indian Names. By this we mean, that it identifies various ways similar-sounding Indian Names have been written/spelled in a particular dataset. The tool assigns a unique alphanumeric ID to each name, and then gives the human user the option to decide if the similar names are the same individual or not. If the user decides that they are the same individual, both names are given the same ID.
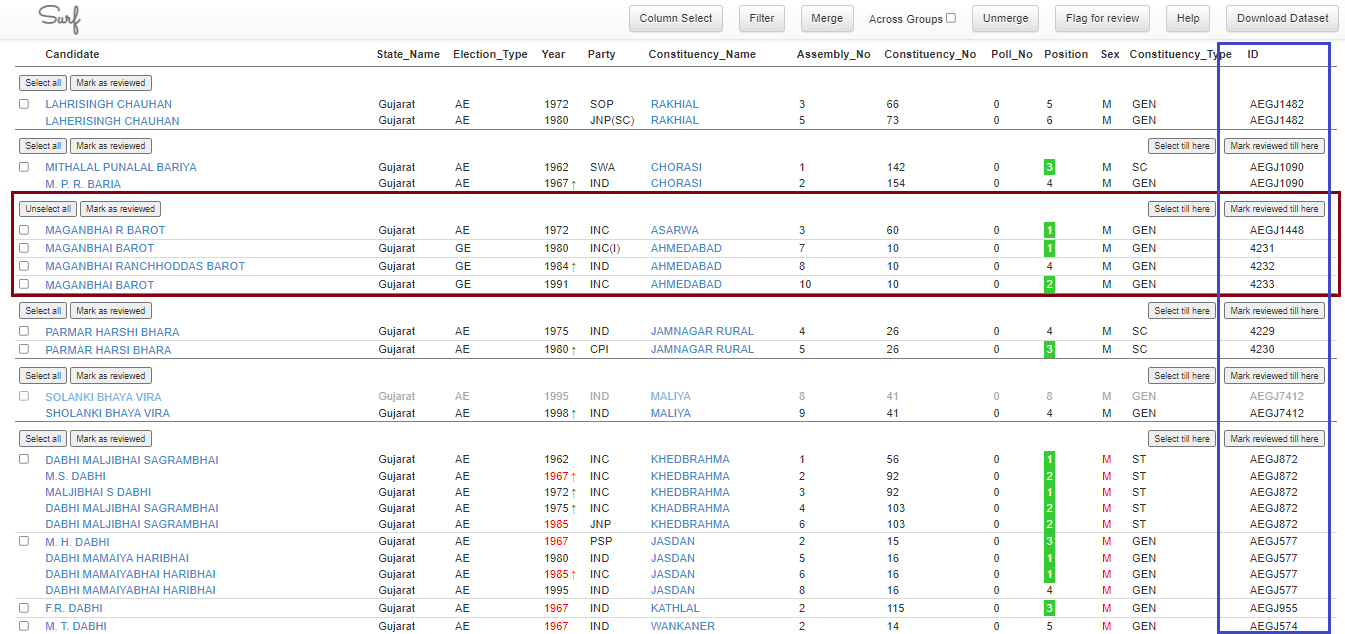
For example, Figure 1 below shows us the suggestions from Surf for a particular set of Names. The tool says that MAGHANBAI BAROT has appeared 3 times in the dataset and they all are probably the same individual, along with MAGHANBAI RANCHHODDAS BAROT. In the right-most corner, we see that all 4 names have different IDs.
Figure 1 : Pre-Merged Names
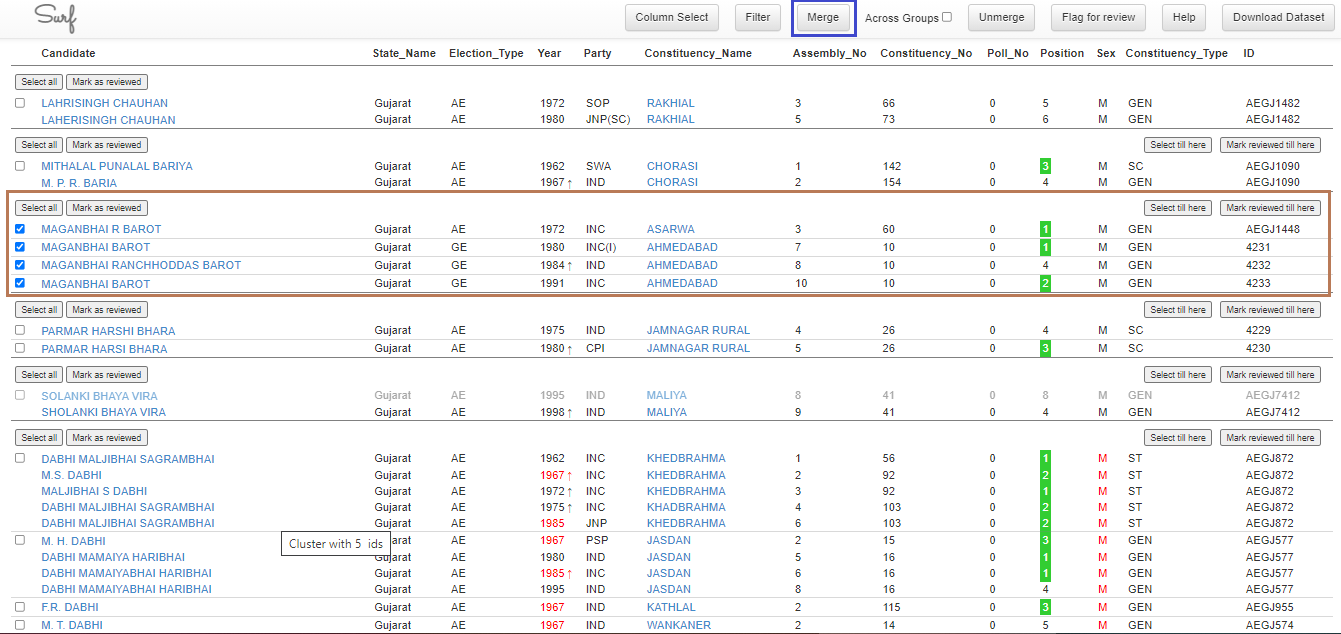
In Figure 2, the corresponding names have been selected. After deciding if they are same individual or not, the user must click on Merge (highlighted in blue)
Figure 2 : Choosing names for merging
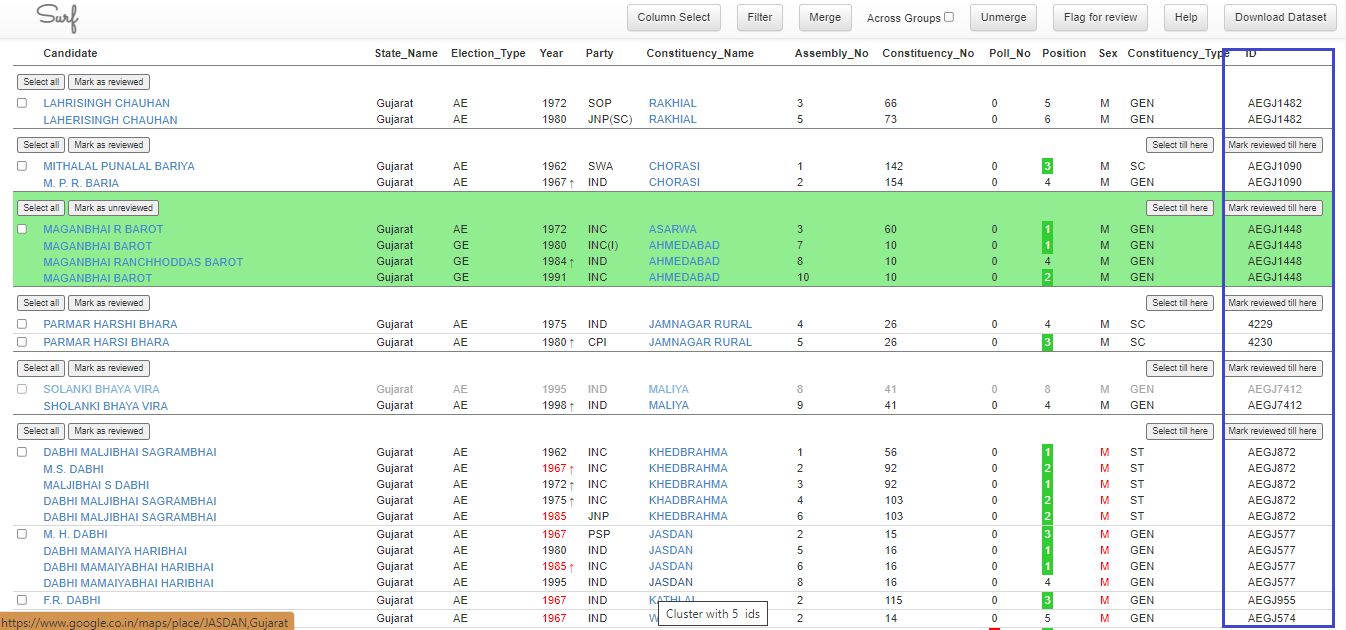
After clicking Merge, all the names have now been given the same ID, as given in Figure 3.
Figure 3: Merged Candidates
The user can also filter candidates based on their requirements. For more details on the User Interface, you may refer to our tutorial video provided in the last section.
Brief Overview of the Algorithms Used
Figure 4 below shows the pre-defined list of algorithms that can currently be run on Surf. Depending on the algorithm chosen, Surf suggests what names might actually be the same individual. It must be noted that none of the algorithms are case sensitive. The final decision rests with the user. We will briefly explain the algorithms in this section.
Figure 4: List of Algorithms available
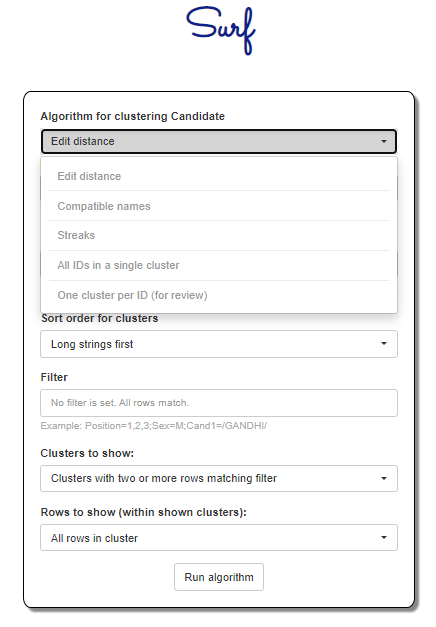
- Edit Distance: This algorithm works based on “Edit Distance”, which is the number of changes required to make one word exactly the same as another. These changes can be in the form of deleted letters, added letters, or even substituted letters.
For example, the Edit Distance between ‘Narendr’ and ‘Narendra’ is 1, since we add an ‘a’ at the end of Narendr to make it the same as Narendra. Similarly, the Edit Distance between ‘Raghav’ and ‘Raghaban’ will be 3, since we add ‘a’ and ‘n’ at the end of Raghav, and replace the ‘v’ in Raghav with a ‘b’ to make it Raghaban.
- Compatible names: This algorithm is used to process names in the form of initials. As a first step, all names are broken down into ‘tokens’. So the name “MUTHUVEL KARUNANIDHI STALIN” will be broken down into 3 tokens – “MUTHUVEL”, “KARUNANIDHI”, and “STALIN”. Similarly “M.K. STALIN” will also be broken down into 3 tokens – “M”, “K”, and “STALIN”.
After breaking names down into tokens, the algorithm compares names using tokens. So continuing with the same example, the 2 names above have the same last token (“STALIN”), but also that “M” from the second name exists in “Muthuvel” and “K” from the second name exists in “Karunanidhi”.
The order of tokens does not matter. Also, this algorithm will give a suggestion only when atleast 1 token is exactly the same between the names. So in the above example, the two names will be suggested together since “STALIN ” is a common token between them. This prevents Surf from giving an overload of low quality suggestions.
- Streaks: Let’s say in our dataset, the candidate M Karunanidhi contested in the following assemblies – 1,2,5,7. Other sources however say the candidate also contested in the 3rd, 4th and 6th assemblies. This algorithm will help us check if we have missed out on potential candidates in our dataset.
Firstly, the user is prompted to choose the ‘streak length’ and ‘maximum holes’, which are used to identify the breaks in the above sequence. For instance, in the above case we have a streak length of 3 [5, 6, 7] with one hole [6] and a streak length of 4 [2,3,4,5] with two holes [3,4].
Secondly, the user is prompted to choose a primary column. The primary column is the sequence column, which for us is always the Assembly Number. This is the most important user setting since this determines the column on which the algorithm will look for streaks.
Finally, the user must choose a secondary column. For our purpose the secondary column is either “Party” or “Constituency Name”. Continuing with M Karunanidhi, we know that he has contested from 2 constituencies – Saidapet and Anna Nagar, and 1 party – DMK. So choosing “Constituency Name” as the secondary column will mean the algorithm will only search for candidates who contested from Saidapet or Anna Nagar when giving suggestions (regardless of Party). Similarly, when choosing “Party”, the algorithm will only give suggestions for candidates that contested from DMK (regardless of constituency). This setting helps the user narrow down on the best possible choices, and prevents an overload of suggestions being thrown up from the algorithm.
- One cluster per ID: This is a review algorithm. It shows all rows of the same ID together. This is useful to review merges and un-merges.
- All IDs in a single cluster: This shows all candidates together. It can be used to view all the data together and then use filters to only see what the user desires.
For more information on the algorithms, please refer to the video link in the next section or send us an email.
Conclusion
Surf is a tool developed by TCDP to resolve Indian Names. The tool assigns a unique alphanumeric ID to each name, which the human user can utilise to track or merge selected candidates. We have used it to resolve names of electoral candidates in our work.
There are currently 5 predefined algorithms which the human analyst can choose from, based upon which Surf suggests what names might be of the same individual. The final decision always rests with the human user.
Currently, there are 5 algorithms to choose from –
- Edit Distance
- Compatible Names
- Streaks
- One cluster per ID
- All IDs in a single cluster
You can find links to more detailed information about Surf from the next section.
Acknowledgements: We thank Priyamvada Trivedi for feedback.
More Resources
To use the software for yourself or your organisation, please download it from here.